

场景:累行客标签有很多,放到一起一团显得没有条理,参考了各平台使用较多的排序,常用的就是以标签的首个字的首字母进行排序。
效果
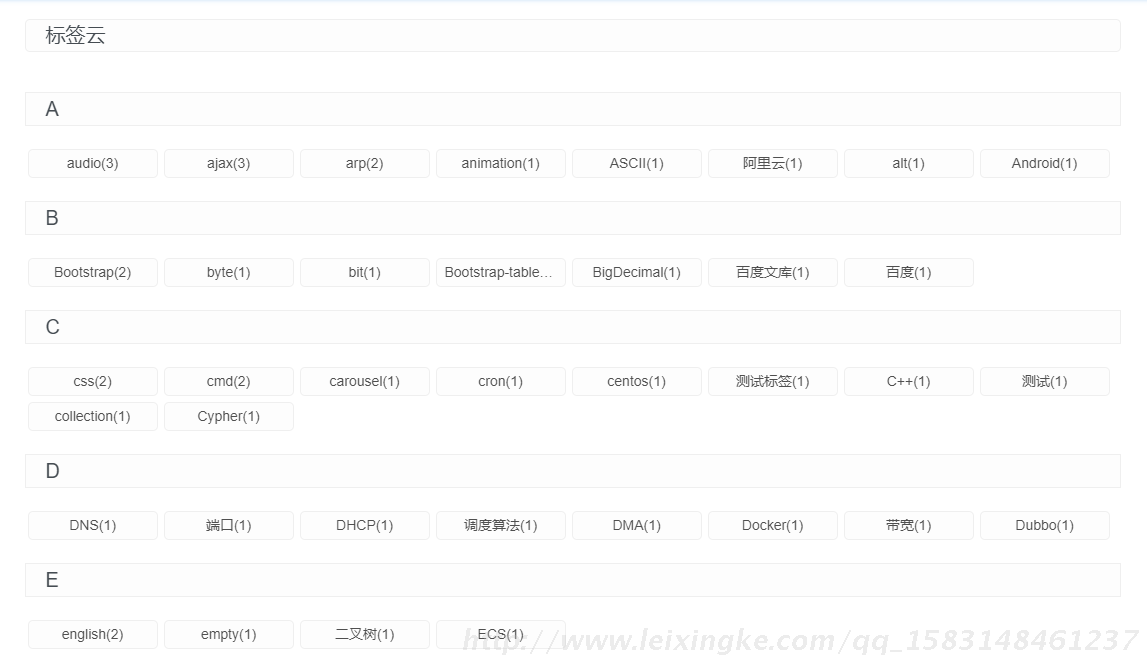
思路:
首先获取标签第一个字符,然后获取字符的首字母,
如果是英文的就直接返回他本身,
如果是汉语,就获取拼音的第一个字符返回,
如果是其他符号,就放到Other里面。
下面是一个demo,理解后,想要实现,上面的效果也就很简单。
复制收展Javapackage com.leixing.blog.util;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import java.io.UnsupportedEncodingException;
import java.util.Collection;
import java.util.Set;
/**
* @Desc -累行客
* @Author luolei
* @Web http://www.leixingke.com/
* @Date 2020/07/09 15:00
* 参考:https://blog.csdn.net/chenbing81/article/details/51960019
* 三个静态方法都可以单独使用。
*/
public class LetterUtils {
private static final int GB_SP_DIFF = 160;
// 存放国标一级汉字不同读音的起始区位码
private static final int[] secPosValueList = { 1601, 1637, 1833, 2078, 2274, 2302, 2433, 2594, 2787, 3106, 3212, 3472, 3635, 3722, 3730, 3858, 4027, 4086, 4390, 4558, 4684, 4925, 5249, 5600 };
// 存放国标一级汉字不同读音的起始区位码对应读音
private static final char[] firstLetter = { 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'w', 'x', 'y', 'z' };
public static void main(String[] args) {
String tags[] = new String[]{"累行客", "Google", "百度", "Java", "数据结构", "端口", "@PathVariable"};
//String tags[] = new String[]{"Google", "@PathVariable"};
JSONObject result = new JSONObject();
for (int i = 0; i < 26; i++) {
result.put(String.valueOf((char)('A' + i)) , new JSONArray()); //初始化结构
}
result.put("Other", new JSONArray());
for (int i = 0; i < tags.length; i++) {
String tag = tags[i];
if(tag == null || tag.length() == 0) continue;
String fchar = tag.substring(0, 1); //只取一个字符
char c = fchar.toCharArray()[0];
Character f = getCharPinyinLetter(c);
String key = "Other";//其他字符
if(f != null){ //汉字或字母
key = String.valueOf(f).toUpperCase();
}
//添加到对应字符列表后
result.getJSONArray(key).add(tag);
}
/* Set<String> strings = result.keySet();
Collection<Object> values = result.values();
System.out.println(strings.iterator().next());
System.out.println(values.iterator().next());*/
for (int i = 0; i < result.size()-1; i++) { //其他不输出
JSONArray arr = result.getJSONArray(String.valueOf((char)('A' + i)));
System.out.println(String.valueOf((char)('A' + i)));
System.out.println("--------------------------------------");
for (int i1 = 0; i1 < arr.size(); i1++) {
System.out.println(arr.getString(i1));
}
System.out.println("--------------------------------------\n");
}
JSONArray arr = result.getJSONArray("Other");
System.out.println("--------------------------------------");
for (int i1 = 0; i1 < arr.size(); i1++) {
System.out.println(arr.getString(i1));
}
}
/**
* @Desc: 获取一段字符串的所有汉字的拼音首字母
* @Date: 2020/7/9 15:09
* @param characters:
* @return: java.lang.String
* 如累行客 返回 lxk
*/
public static String getStrFirstPinyinLetter(String characters) {
StringBuffer buffer = new StringBuffer();
for (int i = 0; i < characters.length(); i++) {
char ch = characters.charAt(i);
if ((ch >> 7) == 0) {
// 判断是否为汉字,如果左移7为为0就不是汉字,否则是汉字
} else {
char spell = getCharPinyinLetter(ch);
buffer.append(String.valueOf(spell));
}
}
return buffer.toString();
}
/**
* @Desc: 获取一个汉字的首字母
* @Date: 2020/7/9 15:10
* @param ch:
* @return: java.lang.Character
*/
public static Character getCharPinyinLetter(char ch) {
byte[] uniCode = null;
try {
uniCode = String.valueOf(ch).getBytes("GBK");
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
return null;
}
if (uniCode[0] < 128 && uniCode[0] > 0) { // 非汉字 字母或其他字符
if((uniCode[0] <= 'Z' && uniCode[0] >= 'A') || (uniCode[0] <= 'z' && uniCode[0] >= 'a') ) return ch; //字母
else return null; //或其他字符
} else { //汉字
return getBytesPinyinLetter(uniCode);
}
}
/**
* 获取一个汉字的拼音首字母。 GB码两个字节分别减去160,转换成10进制码组合就可以得到区位码
* 例如汉字“你”的GB码是0xC4/0xE3,分别减去0xA0(160)就是0x24/0x43
* 0x24转成10进制就是36,0x43是67,那么它的区位码就是3667,在对照表中读音为‘n’
*/
public static char getBytesPinyinLetter(byte[] bytes) {
char result = '-';
int secPosValue = 0;
int i;
for (i = 0; i < bytes.length; i++) {
bytes[i] -= GB_SP_DIFF;
}
secPosValue = bytes[0] * 100 + bytes[1];
for (i = 0; i < 23; i++) {
if (secPosValue >= secPosValueList[i]
&& secPosValue < secPosValueList[i + 1]) {
result = firstLetter[i];
break;
}
}
return result;
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
JAVA中如何获取中文汉字的首字母
参考:https://blog.csdn.net/chenbing81/article/details/51960019